ServeLLM gives developers instant access to open-source LLMs like Qwen and Llama through a fast, OpenAI-compatible API — hosted on region-local infrastructure close to your users.
Everything developers need to ship AI features in production — multi-model API, streaming, playground, observability, and access control, all from one platform.
Switch between Qwen, Llama and more with a single line of code. OpenAI-compatible — your existing SDK works out of the box.
Stream tokens as they're generated for snappy chat-like experiences. Built on a low-latency, region-local inference layer.
Test prompts and compare model outputs side-by-side without writing a single line of code.
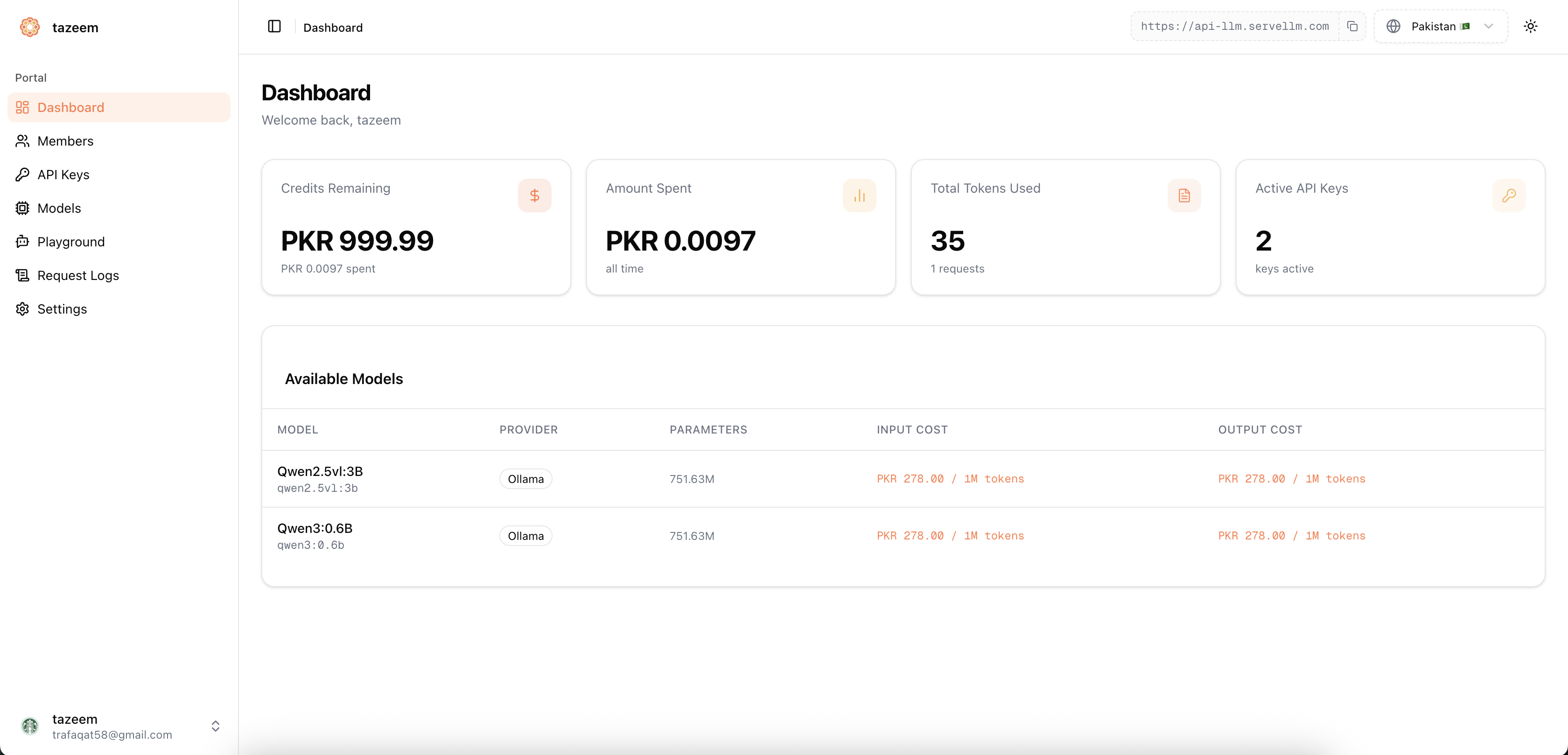
Inspect every request, monitor token usage, and track spend in real time — directly in the dashboard.
Manage keys, scope access, and invite teammates to your organization with role-based permissions.
Your apps hit a single OpenAI-compatible endpoint. ServeLLM handles authentication, routing, and high-throughput serving — so you focus on shipping, not infrastructure.

Just change your API endpoint and keep your existing code. Works with any language or framework.
import openai
client = openai.OpenAI(
api_key="sk-servellm-xxxxxxxxxxxxxxxx",
base_url="https://api-llm.servellm.com/v1"
)
response = client.chat.completions.create(
model="qwen3:0.6b",
messages=[{"role": "user", "content": "Hello!"}]
)ServeLLM routes your request to the right model while tracking usage and performance — across every language and framework.
View full API documentationPay only for what you use — billed in local currency. No USD friction, no conversion fees.
| AI Model | Input Token Price(Per Million Tokens) | Output Token Price(Per Million Tokens) |
|---|---|---|
GPT OSS 120B openai/gpt-oss-120b | PKR 100.00 / 1M | PKR 300.00 / 1M |
GPT OSS 20B openai/gpt-oss-20b | PKR 50.00 / 1M | PKR 200.00 / 1M |
Llama 4 Scout meta-llama/llama-4-scout-17b-16e-instruct | PKR 100.00 / 1M | PKR 250.00 / 1M |
Qwen3 32B 131k qwen/qwen3-32b | PKR 150.00 / 1M | PKR 300.00 / 1M |
* Prices in PKR per million tokens.
ServeLLM is a region-localized LLM inference platform — like an OpenAI-compatible API, but served from infrastructure close to your users and billed in your local currency.
We currently serve all traffic from regional infrastructure in Pakistan. Additional regions are being added based on demand — your data and inference stay close to your users.
Yes. ServeLLM is built on a high-availability inference layer with monitoring, retries, and request logs. Enterprise customers can request dedicated capacity and SLAs.
Developers, startups, and enterprises in emerging markets who want fast, affordable access to open-source LLMs without USD billing or cross-border payment friction.